 https://bitaacademy.com/course/hadoop-training-in-chennai/
https://bitaacademy.com/course/hadoop-training-in-chennai/
What is Hadoop?
Large datasets up to petabytes in size can be processed and stored effectively using the open-source Apache Hadoop framework. Hadoop enables the clustering of several computers to analyze big datasets in parallel more quickly than a single powerful machine to store and process the data.
Roles and Responsibility of Hadoop Developer
- A Hadoop Developer is responsible for creating, running, and debugging sizable Hadoop clusters and writing apps that interact with Hadoop. While working with low-level hardware resources, the developers also provide high-level APIs for creating software.
- Working collaboratively with the development team, evaluate the Big Data infrastructure that is currently in place.
- Create and code Hadoop programs to analyze data assemblages.
- Establish data processing frameworks
- Isolate and extract data clusters
- Scripts for tests that examine outcomes and address faults
- Make documentation and programs for tracking data.
- Maintain data privacy and security.
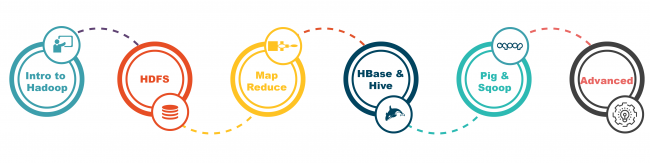
Syllabus for Hadoop Training in Chennai
PART 1: An Overview of Hadoop and Big Data
- High Availability
- Scaling
- Benefits and Challenges
- What do you know Big Data?
- How is Big Data important for Enterprises now?
- Features of Big Data
- What do you know about Hadoop Distributed File System (HDFS)?
- How to Compare Hadoop and SQL?
- How is Enterprises using Hadoop now?
- Deep Dive on Hadoop Architecture
- What do you know Hadoop and HDFS?
- How to use the Hadoop Single node image?
PART 2: Deep dive on HDFS
- Design and Concepts.
- What do you know about Blocks, Nodes and Data nodes?
- More about High Availability and HDFS Federation
- Basics of File System Operations
- Difference between File Read and File Write
- What do you know Block Placement Policy and Modes?
- Deep Dive on Config files
- What do you know about Metadata and Edit log?
- What do you know about secondary name node and safe mode?
- How to add new Data Node?
- Deep Dive on FSCK Utility
- Deep Dive on Zoo Keeper Election Algorithm
PART 3: Map Reduce
- Basis of Map Reduce Program
- How Map Reduce works?
- What do you know about Map Reduce Job Run?
- Overview of Legacy Architecture
- Job Completion and Failures
- Deep Dive on Shuffling and Sorting
- Splits and Record Reader
- Different Types of Partition
- Combiner
- How to optimize JVM Reuse and number of Slots?
- How to compare old and new API?
- What do you know about YARN?
- Map Files
- How to enable compression Codec’s?
- How to use Map Side Join with distributed cache?
- Different Types of I/O formats
- Deep Dive on Input format API and Split API
- How to create Custom Data Type in Hadoop?
PART 4: HBase
- How to Install HBase?
- Deep Dive on Data Model
- Difference between RDBMS and NOSQL
- What do you know master and region servers?
- Catalog Tables
- Block Cache
- Splits
- What do you know about Data Modeling?
- What do you know about Java API and Rest Interface?
- Deep dive on Client Side Buffering
- How to enable replication?
- How to perform RAW Scans?
- Filters
- Bulk Loading
PART 5: Hive
- How to install Hive?
- Architecture
- What do you know about Hive Services?
- Deep Dive on Hive Server and Hive Web Interface (HWI)
- Do you know about Meta Store and Hive QL?
- Difference between OLTP and OLAP
- How to work with tables?
- User Defined Functions
- What do you know about Hive Bucketed Table and Sampling?
- Deep Dive on Dynamic Partition
- Difference between ORDER BY, DISTRIBUTE BY and SORT BY
- What do you know about RC File?
- Deep Dive on Index and Views
- How to enable update in Hive?
- Log Analysis
- How to access HBASE tables using Hive?
PART 6: Pig
- How to Install Pig?
- Different Types of Execution
- What do you know about Grunt Shell?
- Pig Latin
- Data Processing
- Deep Dive on Primitive Data Types and Complex Data Types
- Different Types of Schema
- What do you know about Loading and Storing?
- Filter
- Group
- Types of Join
- How to use debugging commands?
- Validations
- Type Casting in Pig
- How to work with Functions?
- Splits
- How to execute multiple queries?
- How to handle Errors?
- Difference between Flatten and Order By
- What do you know about Piggy Bank?
- How to access HBASE?
PART 7: SQOOP
- How to install Sqoop?
- How to import Data?
- Incremental Import
- Deep Dive on Free form query import
- How to export data to RDBMS?
- How to export data to HIVE and HBASE?
PART 8: HCatalog
- How to install HCatalog?
- Overview
- Hands on Exercises
PART 9: Flume
- How to install Flume?
- Overview of Flume
- What do you know about Flume Agents?
- Different Types of Flume Agents?
- Deep Dive on Flume commands
- How to log user information using Java Program?
- Use Case of Flume
PART 11: Spark
- What is Apache Spark?
- Deep Dive on Spark Ecosystem
- What do you know about Spark components?
- What is Scala?
- Why do you need to learn Scala?
- Deep Dive on Spark Context
PART 12: Apache Zoo Keeper
- Workflow
- Overview of Zoo Keeper
- What do you know about components?
- Deep Dive on Web Console
- How to integrate HBASE with Hive and PIG?
PART 11: Hadoop Admin
- How to create a 4-node cluster?
- Do you know to configure cluster?
- How do we need to maintain, monitor and Troubleshoot Hadoop Admin?
- How to connect ETL with Hadoop Ecosystem?
Hadoop Certification Training
Completing a Hadoop certification is more of a requirement than an option if you want to advance your career in the Big Data industry. Any Hadoop professional’s resume must, in any instance, have the proper qualifications for themselves with the Hadoop certifications. It increases the likelihood that the candidate’s credentials will be regarded as legitimate and suitable for the needs that Organization frequently watches out for. We are attempting to explore one of the most expensive certification programs because only a small number of them exist. Most certification programs cost little more than a test. The most important core ideas in both the Apache Hadoop and Apache Spark ecosystems are the subject of Cloudera’s Hadoop Certification. The Cloudera Hadoop distribution or any other single Hadoop vendor would not likely be covered in the Hadoop certification exams. Because it tests your Hadoop knowledge regardless of the Hadoop distribution you use, this certification is quite valuable. The Hadoop Training in Chennai offered by BITA will give you the assurance you need to succeed in your exams.
- Cloudera Certified Professional (Data Engineer)
- Cloudera Certified Professional (Data Scientist)
- Cloudera Certified Associate Hadoop and Spark Developer (CCAHD)
- Cloudera Certified Associate Administrator for Apache Hadoop (CCAH)
Job Opportunities in Hadoop
The software industry has made big data accessible, and there are plenty of career opportunities at companies like IBM, Microsoft, Oracle, and others. The demand for analytics professionals is high across several industries, including IT, healthcare, and transportation. Hadoop developers typically earn between $10 and $15 per hour, and demand for their skills increases by 25% annually. To ensure that Hadoop administration runs successfully for all of the diverse customer backgrounds, they must serve as the sole point of management. They ought to be well-versed in Java applications and perceptive of important data principles. The average yearly income for a Hadoop Developer in India is 5.4 Lakhs, with salaries ranging from 3.2 Lakhs to 10.5 Lakhs. Signup for Hadoop Training in Chennai.
The following are some of the
- Hadoop Developer
- Hadoop Engineer
- Hadoop Administrator
- Hadoop Architect
Why should you select us?
- You will know to handle enormous clustered data and structure it once you complete the Hadoop Training in Chennai.
- We offer the Best Hadoop Training for Professionals and students who want to start their careers in Big Data and Analytics.
- Our trainer’s teaching skill is excellent, and they are very polite when clearing doubts.
- We conduct mock tests that will be useful for your Hadoop Interview Preparation.
- Even after completing your Hadoop Training in Chennai, you will get lifetime support from us.
- We know the IT market, and our Hadoop content aligns with the latest trend.
- We provide classroom training with all essential preventative precautions.
- We provide Hadoop Online training on live meetings with recordings.
What is Hadoop?
Large datasets up to petabytes in size can be processed and stored effectively using the open-source Apache Hadoop framework. Hadoop enables the clustering of several computers to analyze big datasets in parallel more quickly than a single powerful machine to store and process the data.
Roles and Responsibility of Hadoop Developer
- A Hadoop Developer is responsible for creating, running, and debugging sizable Hadoop clusters and writing apps that interact with Hadoop. While working with low-level hardware resources, the developers also provide high-level APIs for creating software.
- Working collaboratively with the development team, evaluate the Big Data infrastructure that is currently in place.
- Create and code Hadoop programs to analyze data assemblages.
- Establish data processing frameworks
- Isolate and extract data clusters
- Scripts for tests that examine outcomes and address faults
- Make documentation and programs for tracking data.
- Maintain data privacy and security.
Syllabus for Hadoop Training in Chennai
PART 1: An Overview of Hadoop and Big Data
- High Availability
- Scaling
- Benefits and Challenges
- What do you know Big Data?
- How is Big Data important for Enterprises now?
- Features of Big Data
- What do you know about Hadoop Distributed File System (HDFS)?
- How to Compare Hadoop and SQL?
- How is Enterprises using Hadoop now?
- Deep Dive on Hadoop Architecture
- What do you know Hadoop and HDFS?
- How to use the Hadoop Single node image?
PART 2: Deep dive on HDFS
- Design and Concepts.
- What do you know about Blocks, Nodes and Data nodes?
- More about High Availability and HDFS Federation
- Basics of File System Operations
- Difference between File Read and File Write
- What do you know Block Placement Policy and Modes?
- Deep Dive on Config files
- What do you know about Metadata and Edit log?
- What do you know about secondary name node and safe mode?
- How to add new Data Node?
- Deep Dive on FSCK Utility
- Deep Dive on Zoo Keeper Election Algorithm
PART 3: Map Reduce
- Basis of Map Reduce Program
- How Map Reduce works?
- What do you know about Map Reduce Job Run?
- Overview of Legacy Architecture
- Job Completion and Failures
- Deep Dive on Shuffling and Sorting
- Splits and Record Reader
- Different Types of Partition
- Combiner
- How to optimize JVM Reuse and number of Slots?
- How to compare old and new API?
- What do you know about YARN?
- Map Files
- How to enable compression Codec’s?
- How to use Map Side Join with distributed cache?
- Different Types of I/O formats
- Deep Dive on Input format API and Split API
- How to create Custom Data Type in Hadoop?
PART 4: HBase
- How to Install HBase?
- Deep Dive on Data Model
- Difference between RDBMS and NOSQL
- What do you know master and region servers?
- Catalog Tables
- Block Cache
- Splits
- What do you know about Data Modeling?
- What do you know about Java API and Rest Interface?
- Deep dive on Client Side Buffering
- How to enable replication?
- How to perform RAW Scans?
- Filters
- Bulk Loading
PART 5: Hive
- How to install Hive?
- Architecture
- What do you know about Hive Services?
- Deep Dive on Hive Server and Hive Web Interface (HWI)
- Do you know about Meta Store and Hive QL?
- Difference between OLTP and OLAP
- How to work with tables?
- User Defined Functions
- What do you know about Hive Bucketed Table and Sampling?
- Deep Dive on Dynamic Partition
- Difference between ORDER BY, DISTRIBUTE BY and SORT BY
- What do you know about RC File?
- Deep Dive on Index and Views
- How to enable update in Hive?
- Log Analysis
- How to access HBASE tables using Hive?
PART 6: Pig
- How to Install Pig?
- Different Types of Execution
- What do you know about Grunt Shell?
- Pig Latin
- Data Processing
- Deep Dive on Primitive Data Types and Complex Data Types
- Different Types of Schema
- What do you know about Loading and Storing?
- Filter
- Group
- Types of Join
- How to use debugging commands?
- Validations
- Type Casting in Pig
- How to work with Functions?
- Splits
- How to execute multiple queries?
- How to handle Errors?
- Difference between Flatten and Order By
- What do you know about Piggy Bank?
- How to access HBASE?
PART 7: SQOOP
- How to install Sqoop?
- How to import Data?
- Incremental Import
- Deep Dive on Free form query import
- How to export data to RDBMS?
- How to export data to HIVE and HBASE?
PART 8: HCatalog
- How to install HCatalog?
- Overview
- Hands on Exercises
PART 9: Flume
- How to install Flume?
- Overview of Flume
- What do you know about Flume Agents?
- Different Types of Flume Agents?
- Deep Dive on Flume commands
- How to log user information using Java Program?
- Use Case of Flume
PART 11: Spark
- What is Apache Spark?
- Deep Dive on Spark Ecosystem
- What do you know about Spark components?
- What is Scala?
- Why do you need to learn Scala?
- Deep Dive on Spark Context
PART 12: Apache Zoo Keeper
- Workflow
- Overview of Zoo Keeper
- What do you know about components?
- Deep Dive on Web Console
- How to integrate HBASE with Hive and PIG?
PART 11: Hadoop Admin
- How to create a 4-node cluster?
- Do you know to configure cluster?
- How do we need to maintain, monitor and Troubleshoot Hadoop Admin?
- How to connect ETL with Hadoop Ecosystem?
Hadoop Certification Training
Completing a Hadoop certification is more of a requirement than an option if you want to advance your career in the Big Data industry. Any Hadoop professional’s resume must, in any instance, have the proper qualifications for themselves with the Hadoop certifications. It increases the likelihood that the candidate’s credentials will be regarded as legitimate and suitable for the needs that Organization frequently watches out for. We are attempting to explore one of the most expensive certification programs because only a small number of them exist. Most certification programs cost little more than a test. The most important core ideas in both the Apache Hadoop and Apache Spark ecosystems are the subject of Cloudera’s Hadoop Certification. The Cloudera Hadoop distribution or any other single Hadoop vendor would not likely be covered in the Hadoop certification exams. Because it tests your Hadoop knowledge regardless of the Hadoop distribution you use, this certification is quite valuable. The Hadoop Training in Chennai offered by BITA will give you the assurance you need to succeed in your exams.
- Cloudera Certified Professional (Data Engineer)
- Cloudera Certified Professional (Data Scientist)
- Cloudera Certified Associate Hadoop and Spark Developer (CCAHD)
- Cloudera Certified Associate Administrator for Apache Hadoop (CCAH)
Job Opportunities in Hadoop
The software industry has made big data accessible, and there are plenty of career opportunities at companies like IBM, Microsoft, Oracle, and others. The demand for analytics professionals is high across several industries, including IT, healthcare, and transportation. Hadoop developers typically earn between $10 and $15 per hour, and demand for their skills increases by 25% annually. To ensure that Hadoop administration runs successfully for all of the diverse customer backgrounds, they must serve as the sole point of management. They ought to be well-versed in Java applications and perceptive of important data principles. The average yearly income for a Hadoop Developer in India is 5.4 Lakhs, with salaries ranging from 3.2 Lakhs to 10.5 Lakhs. Signup for Hadoop Training in Chennai.
The following are some of the
- Hadoop Developer
- Hadoop Engineer
- Hadoop Administrator
- Hadoop Architect
Why should you select us?
- You will know to handle enormous clustered data and structure it once you complete the Hadoop Training in Chennai.
- We offer the Best Hadoop Training for Professionals and students who want to start their careers in Big Data and Analytics.
- Our trainer’s teaching skill is excellent, and they are very polite when clearing doubts.
- We conduct mock tests that will be useful for your Hadoop Interview Preparation.
- Even after completing your Hadoop Training in Chennai, you will get lifetime support from us.
- We know the IT market, and our Hadoop content aligns with the latest trend.
- We provide classroom training with all essential preventative precautions.
- We provide Hadoop Online training on live meetings with recordings.